I know many of these statistics are out there on the internet, but searching for them takes time, so this post collects a bunch of them in one place.
English Language Statistics
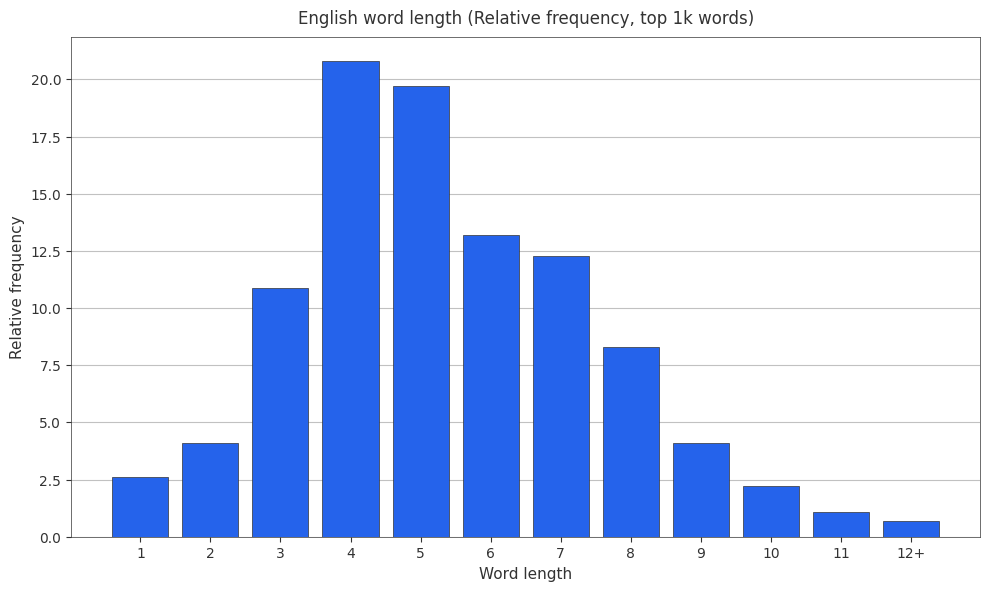
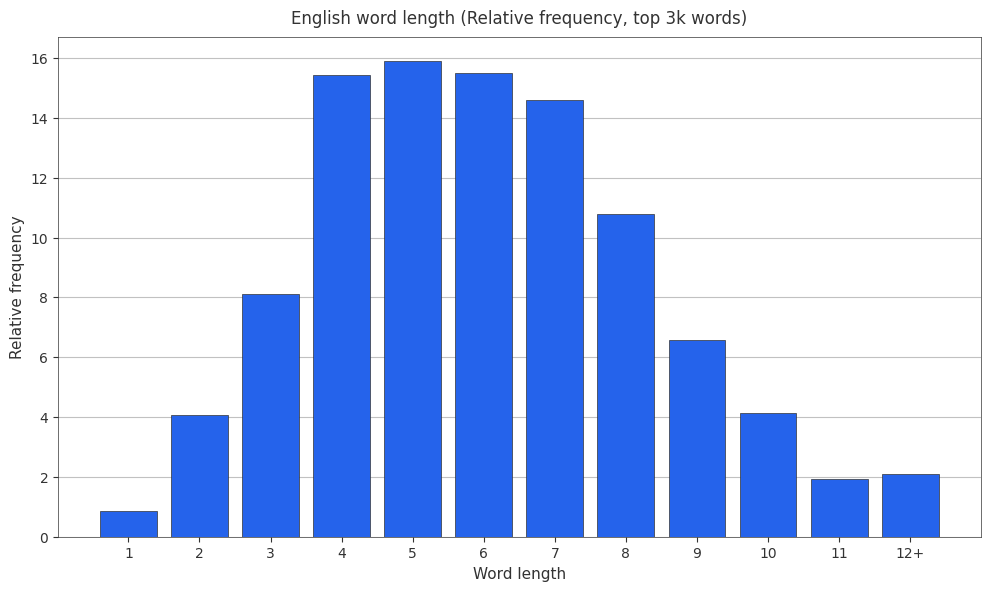
Peter Norvig has a list of the 100,000 most frequent english words derived from the “Google Web Trillion Word Corpus” 1.
English Word Length Relative Frequencies
I like relative frequencies, so here are some histograms showing english word length and relative frequency.
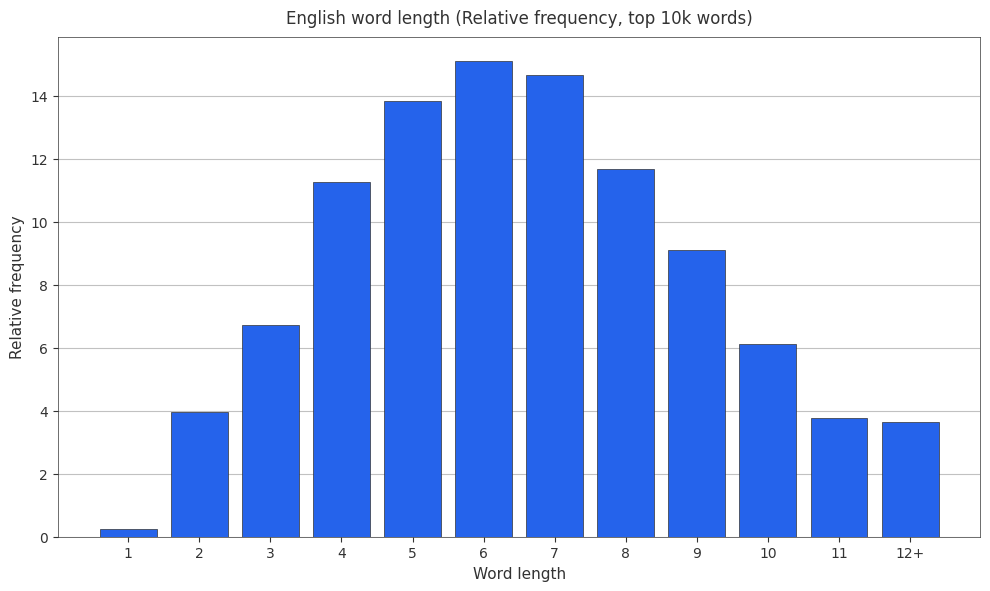
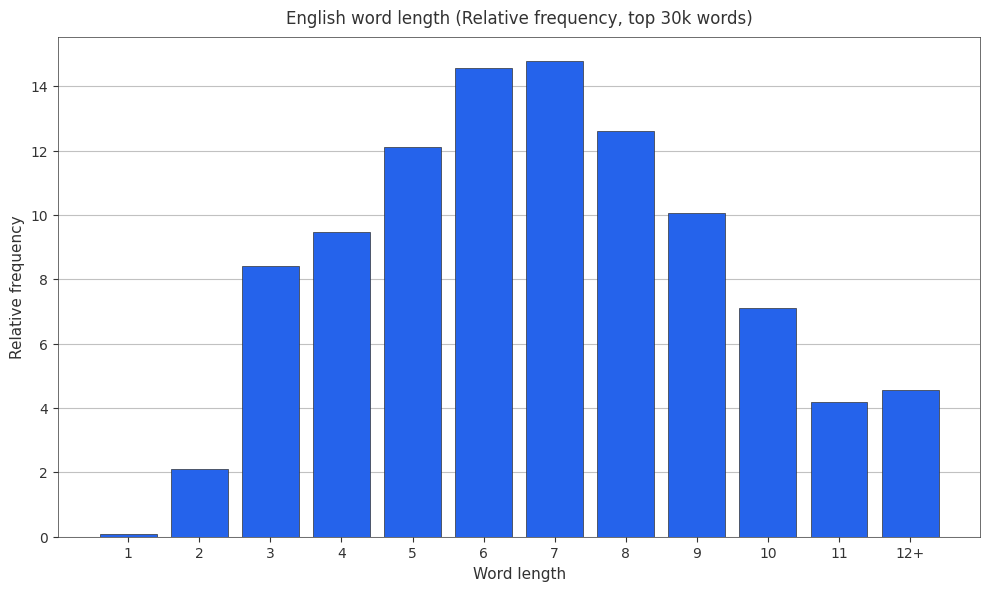
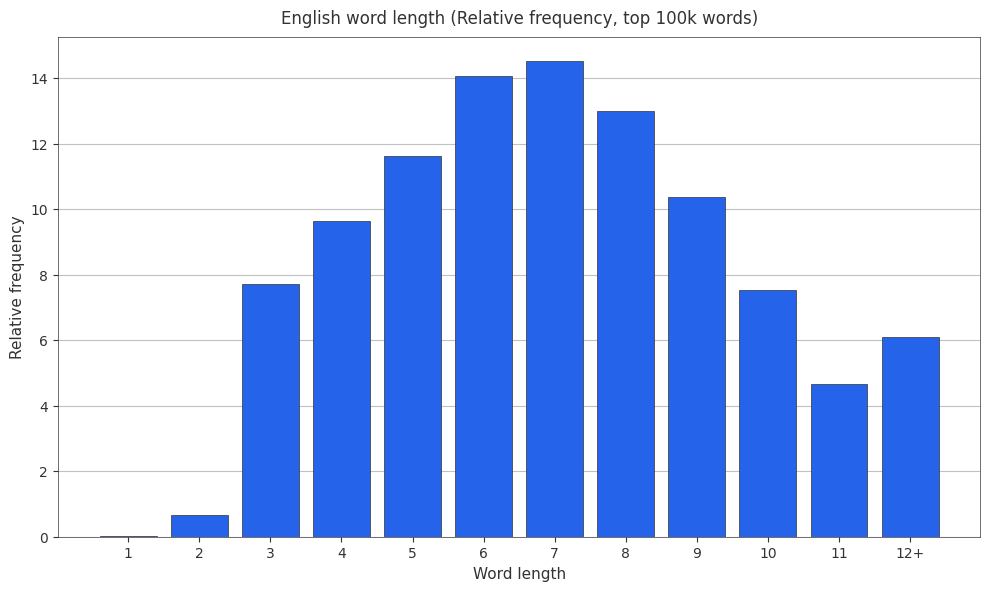
English Word Length Cumulative Frequencies
It’s also useful to have cumulative frequencies around, so here are the cumulative frequencies.
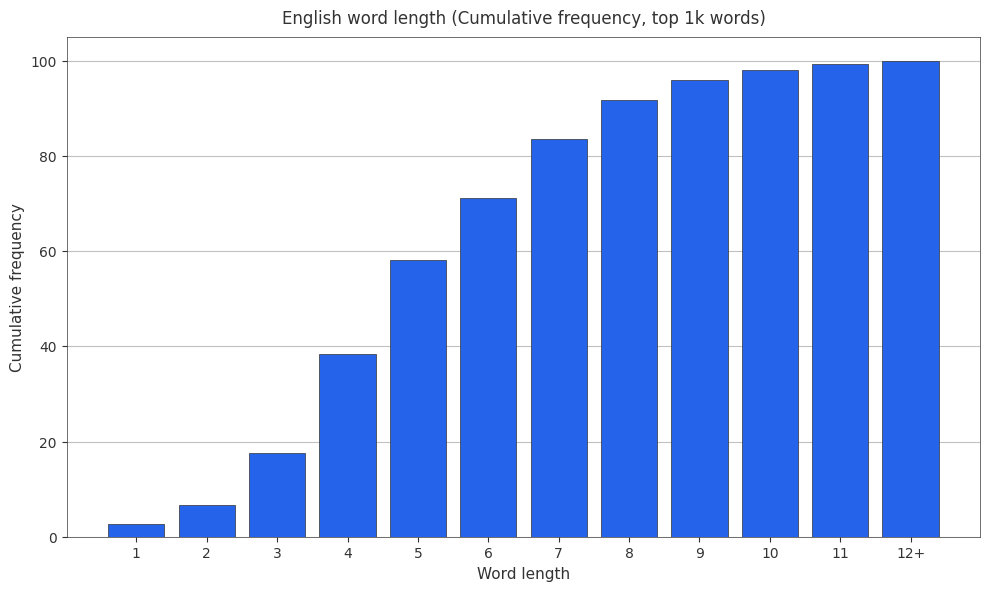
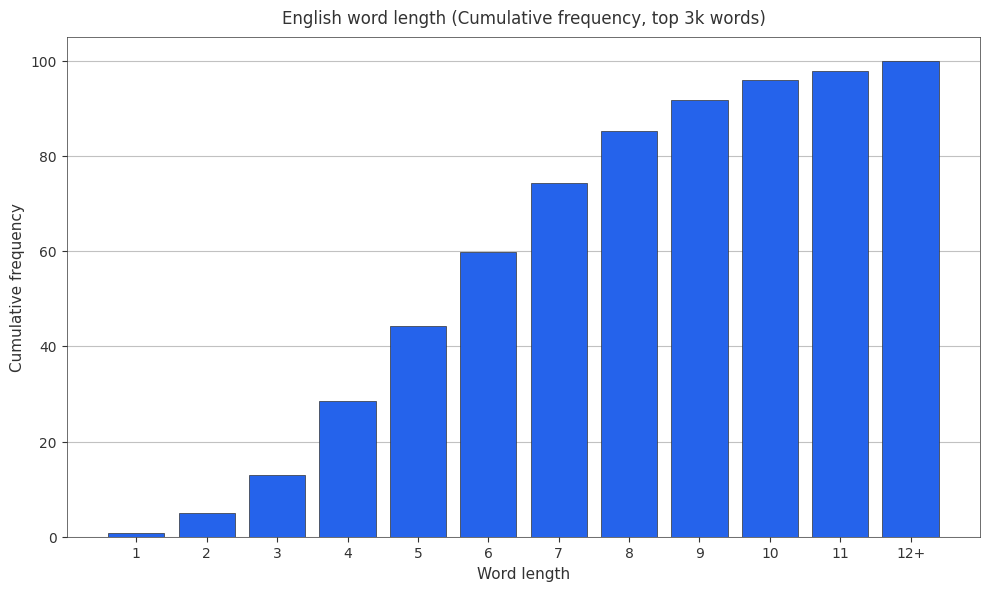
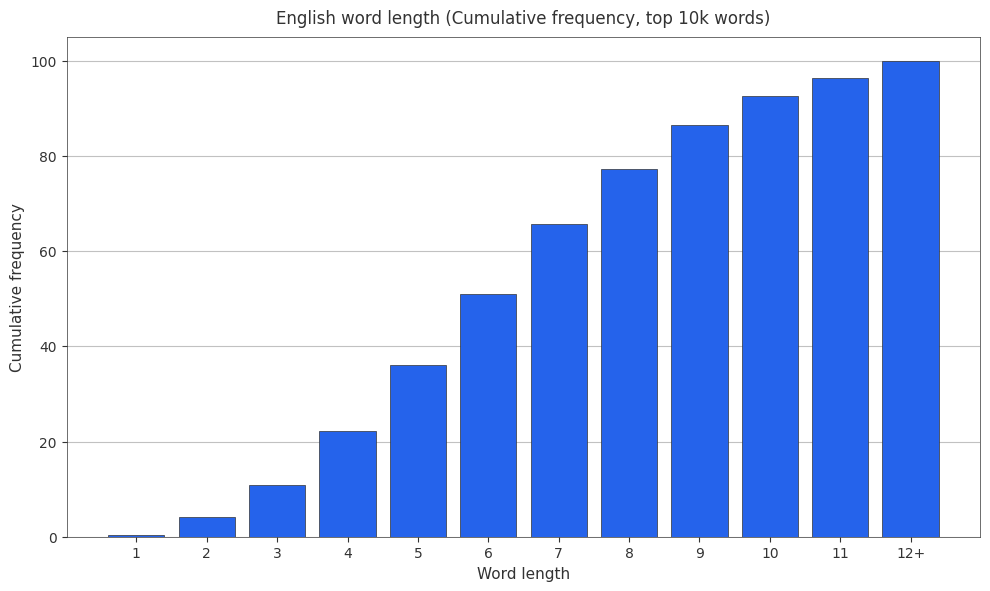
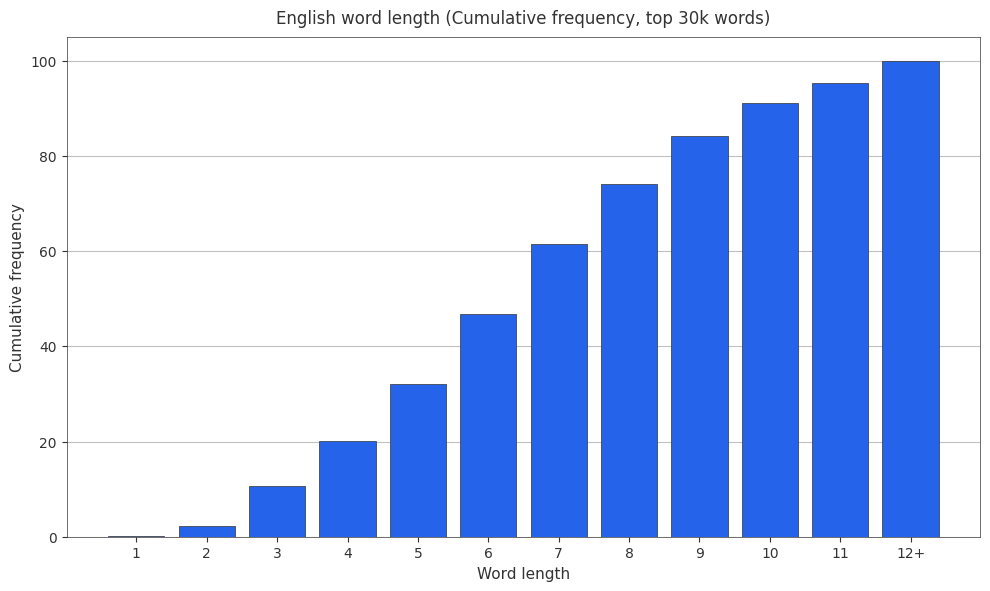
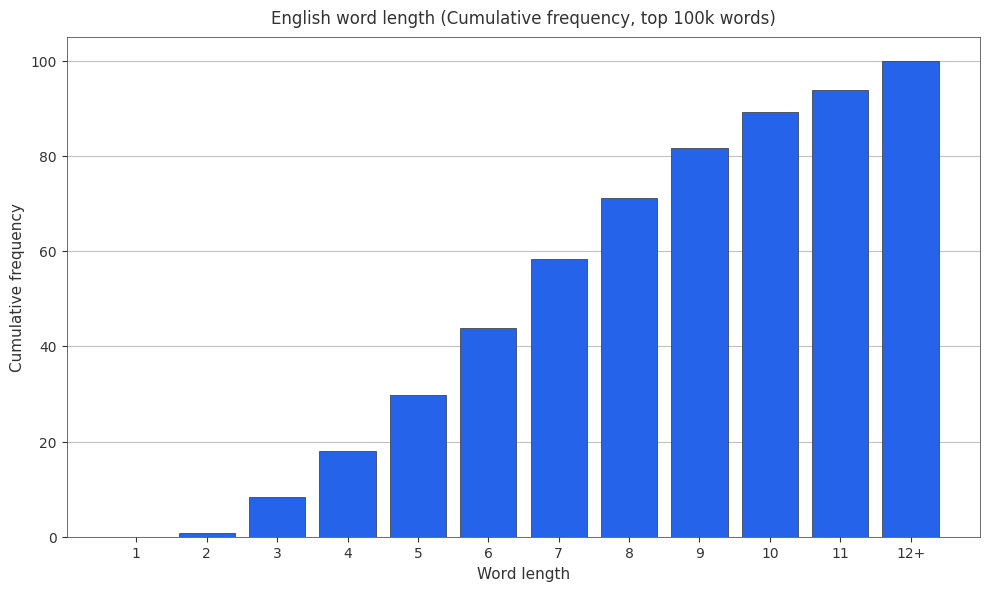
Tokenizer Statistics
Tiktoken is a “fast BPE tokeniser for use with OpenAI’s models”. I was curious what token lengths looked like in the past, so I generated plots, treating OpenAI’s tokenizers as (mostly) representative of most Tokenizers.
Disclaimer: I took the bytes and converted them into utf-8 strings and computed the length. I think this should be fine but I haven’t checked this as closely as I normally would.
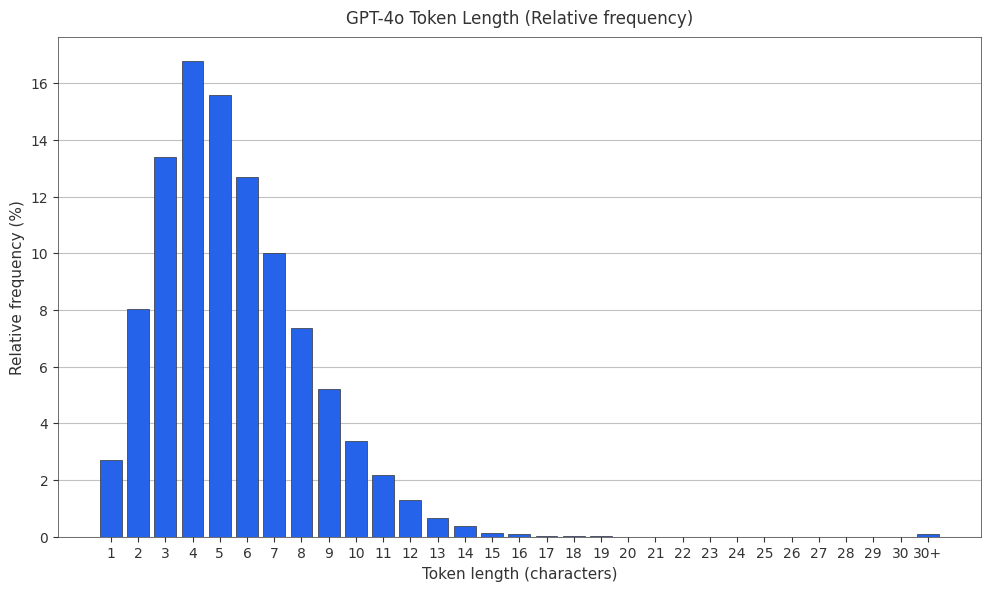
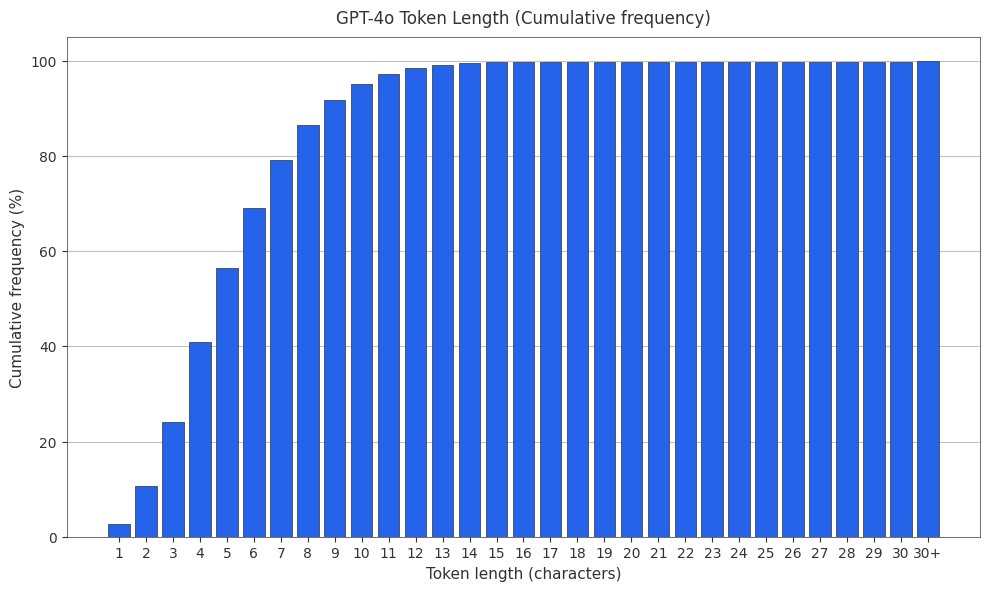
The GPT-4o Tokenizer
The GPT-4o tokenizer is o200k_base2. Both the PMF and CMF are plotted below.
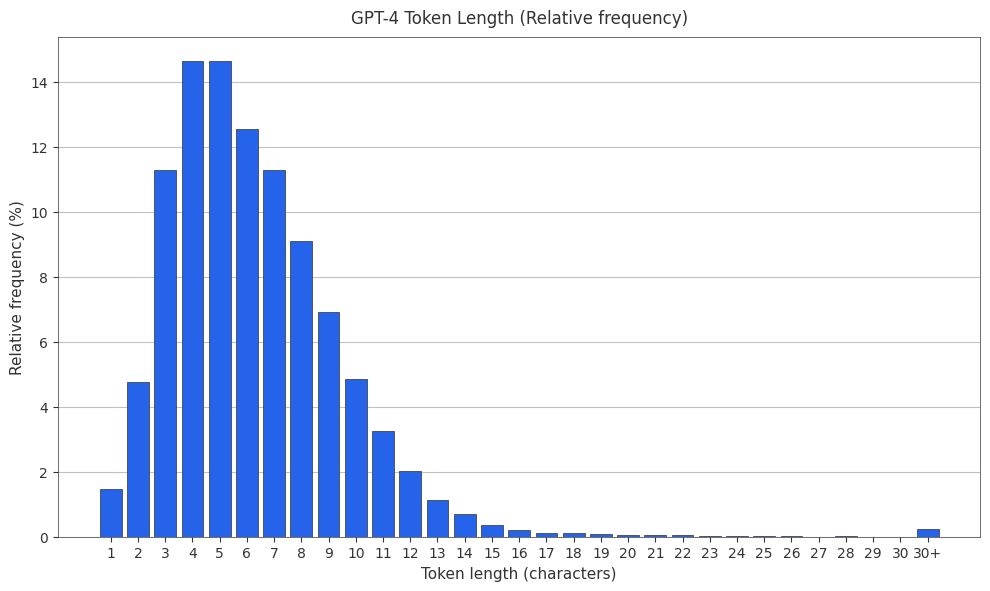
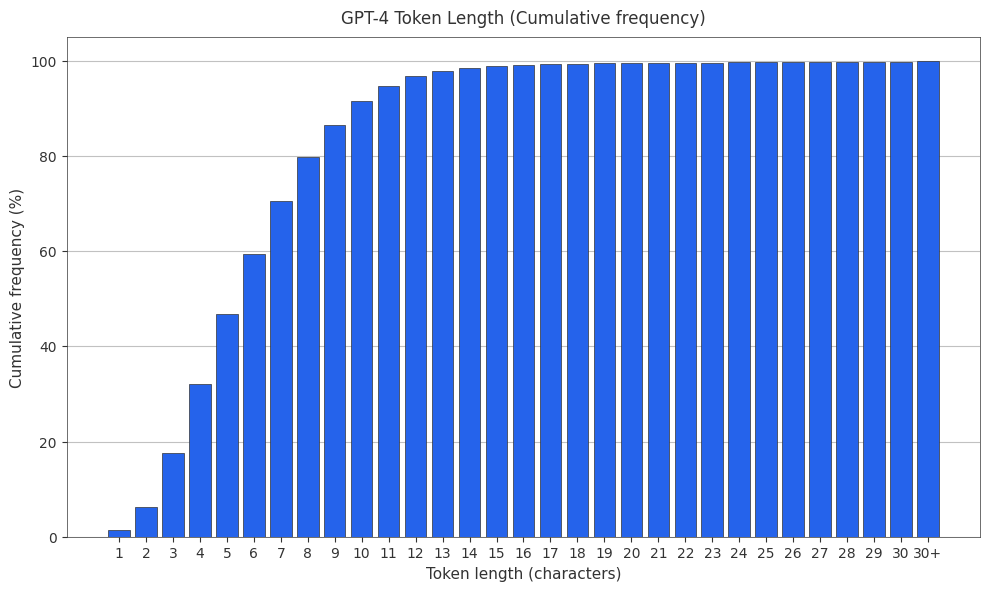
The GPT-4 Tokenizer
The GPT-4 tokenizer is cl100k_base2 . Both the PMF and CMF are plotted below.
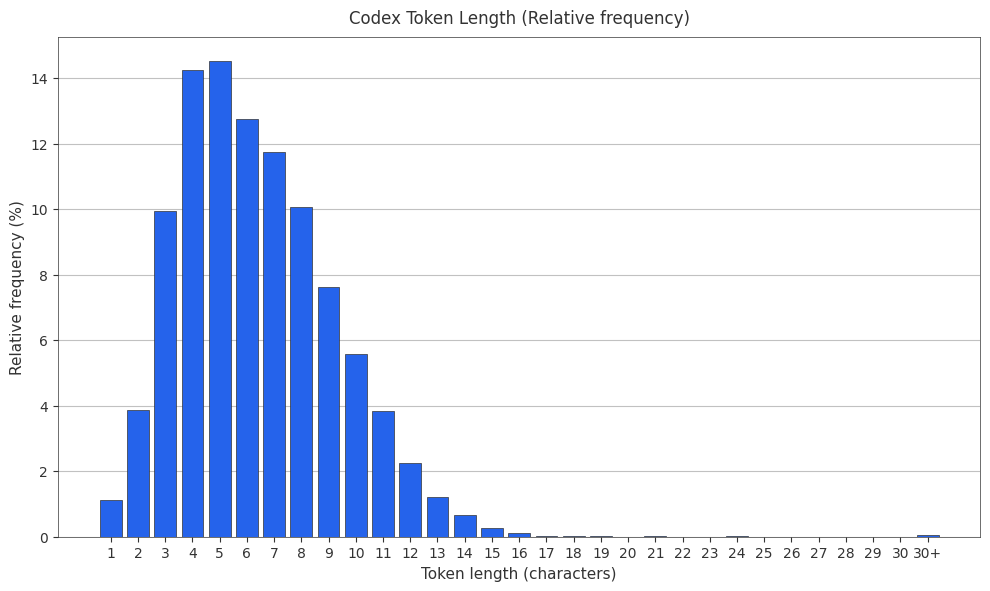
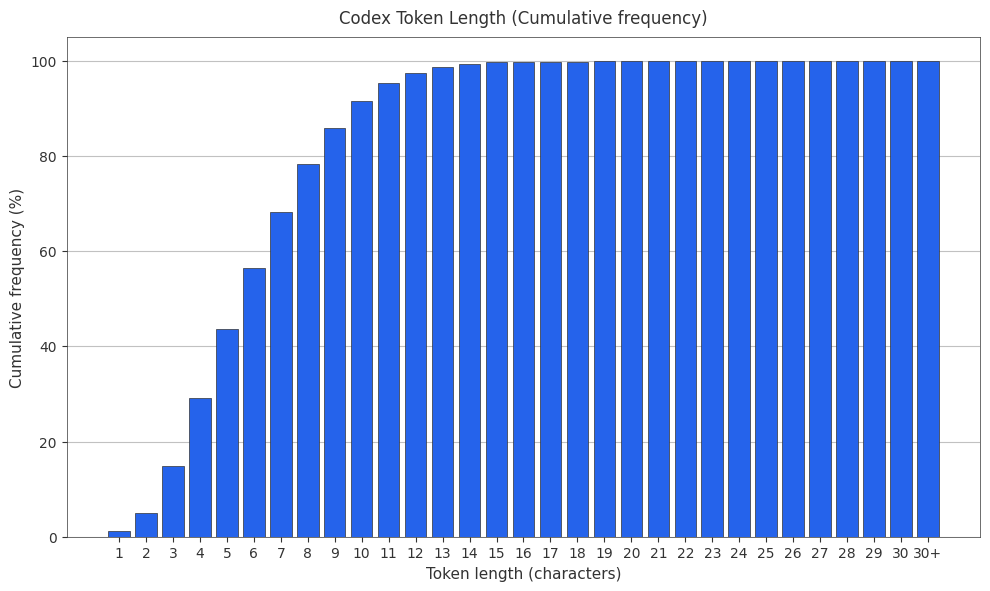
The Codex Tokenizer
The codex tokenizer is p50k_base. PMF and CMF found below.
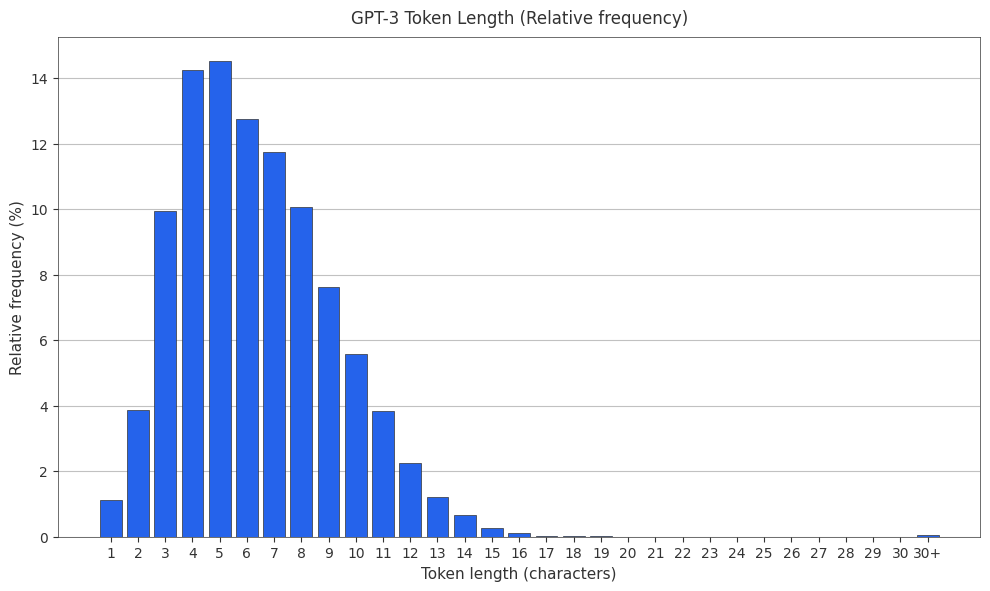
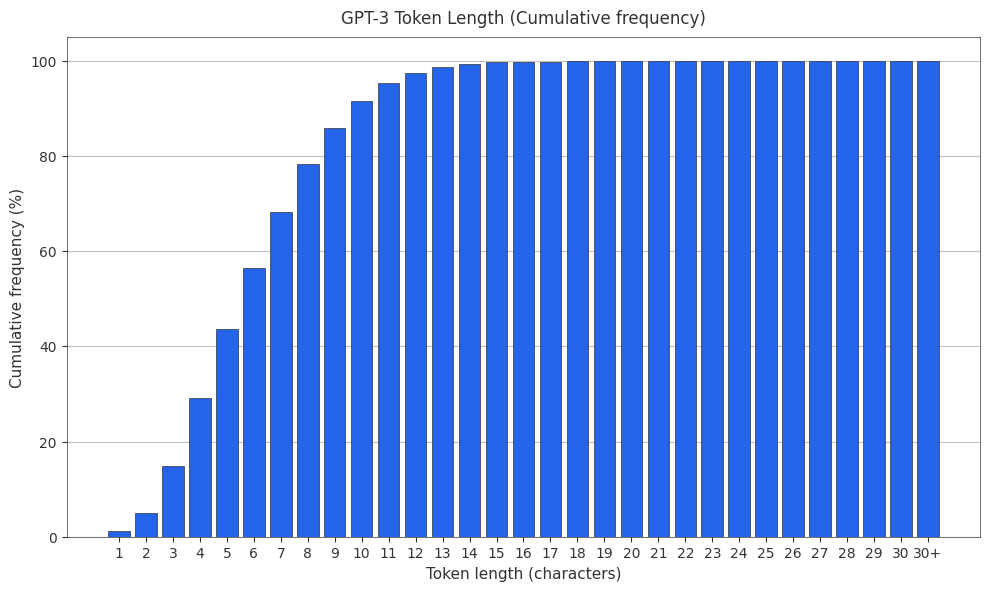
The GPT-3 Tokenizer
The original GPT-3 tokenizer is r50k_base. PMF and CMF found below.
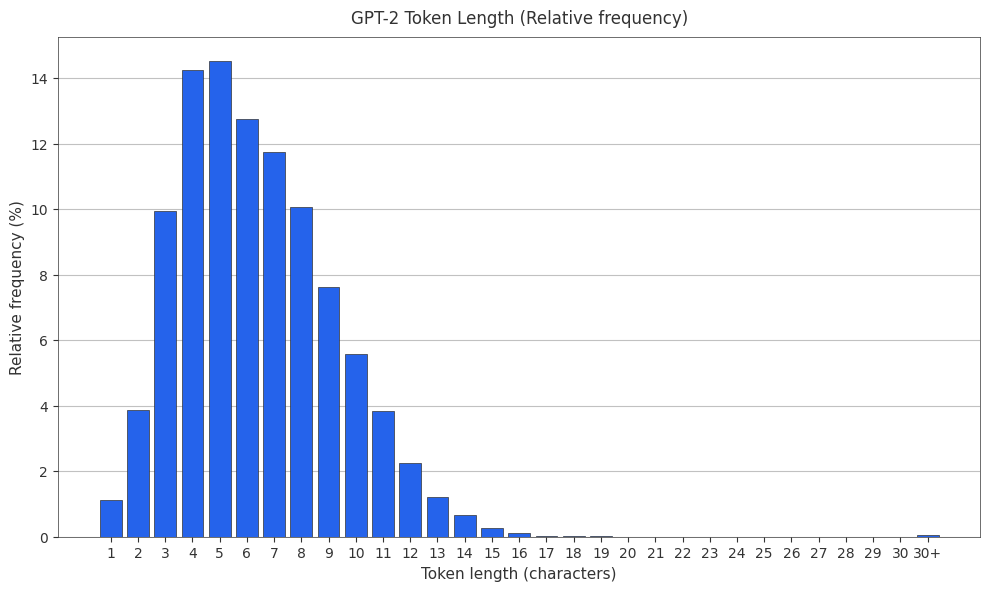
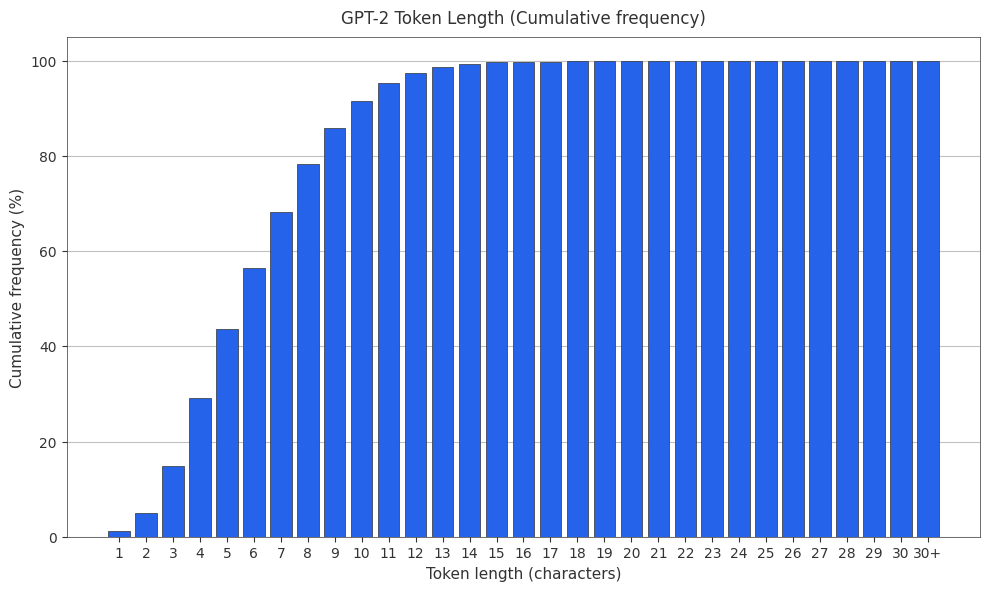
The GPT-2 Tokenizer
The original GPT-2 tokenizer is gpt-2. PMF and CMF found below.
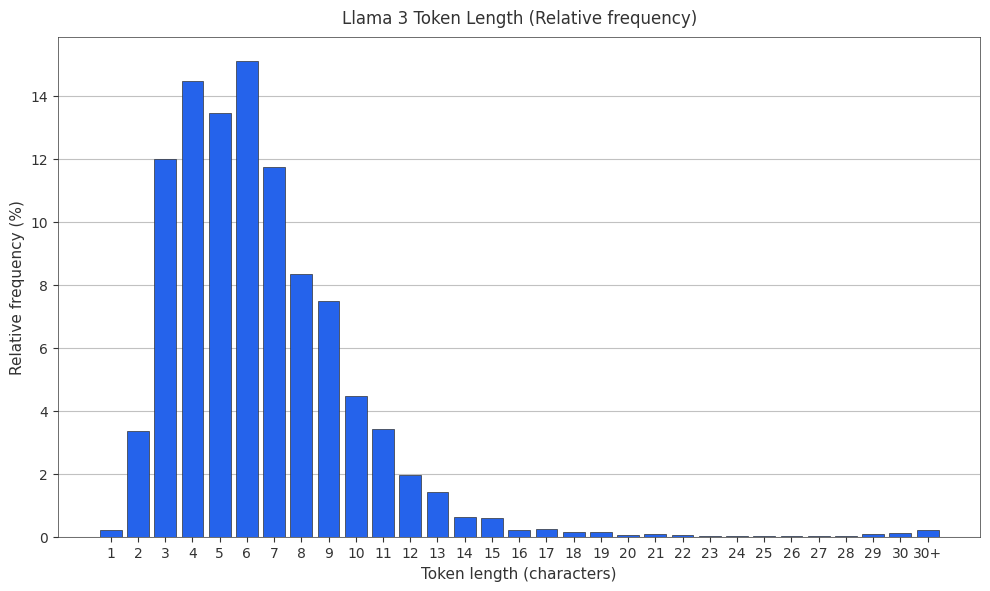
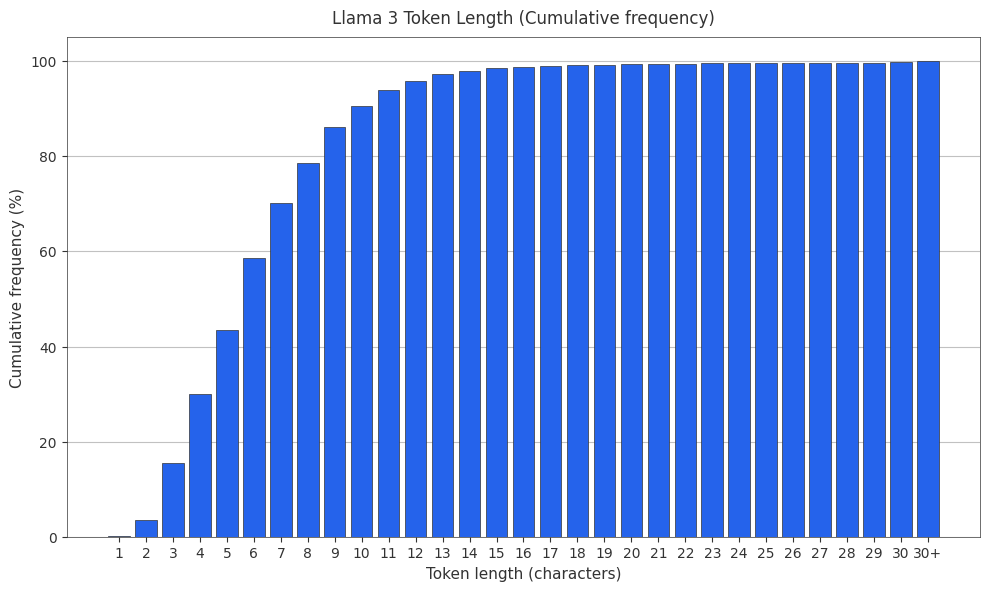
The Llama 3 Tokenizer
The Llama 3 tokenizer (not included in tiktoken) has a surprising token length distribution 3.
The Gemma Tokenizer
Google’s Gemma family uses a SentencePiece-based tokenizer with ~256k vocabulary size—the largest among major models.
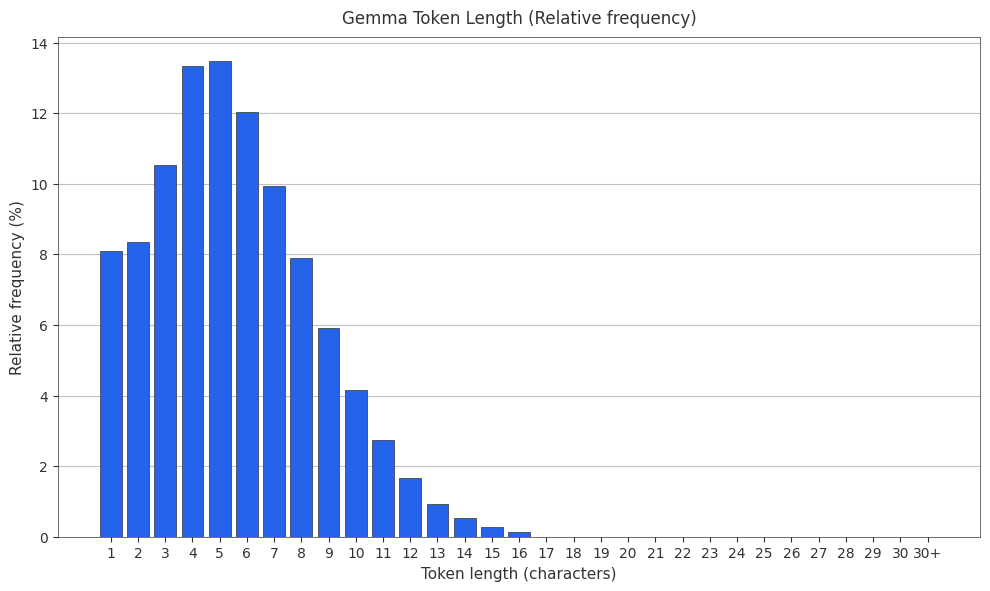
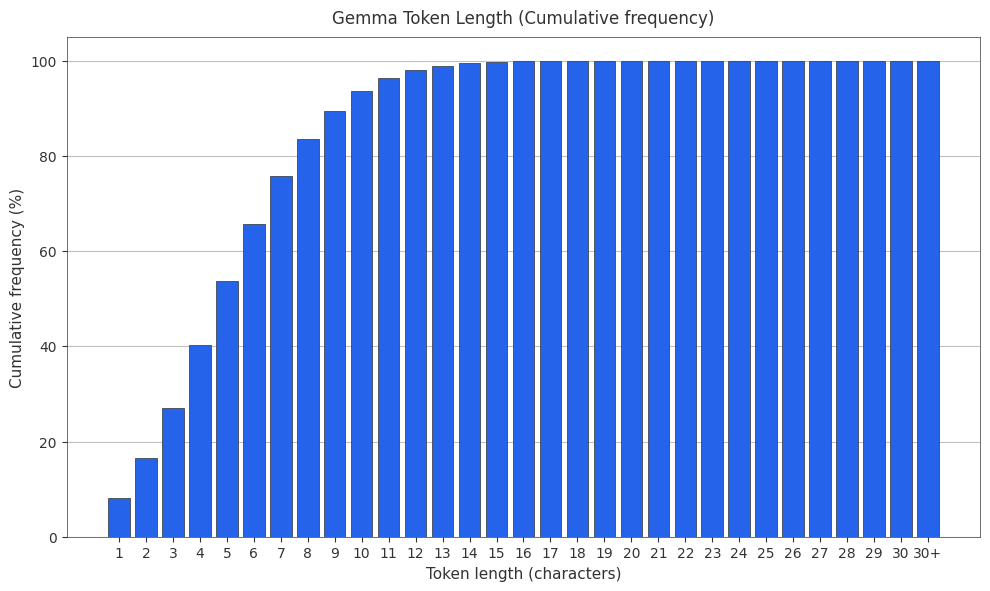
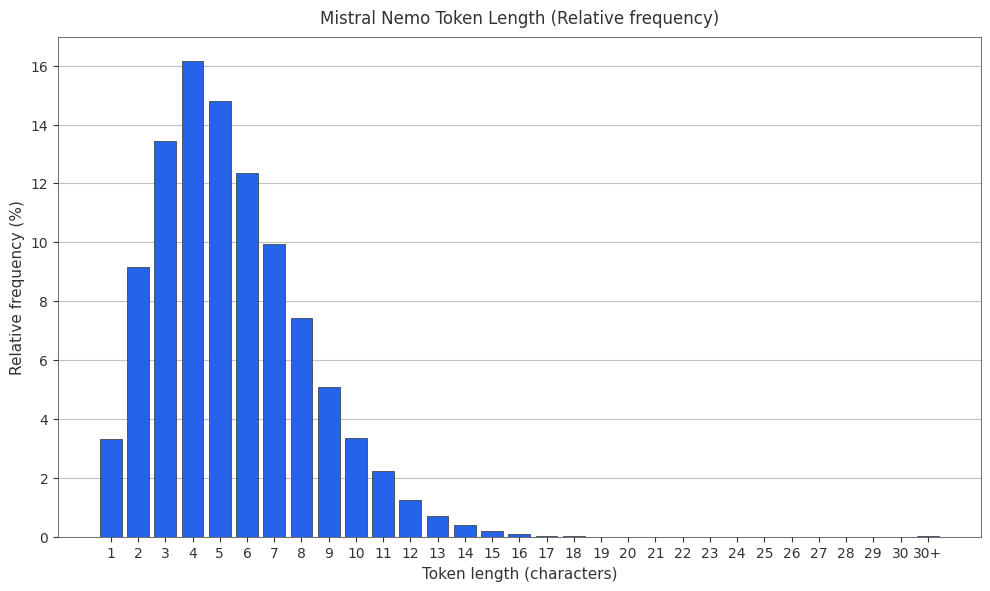
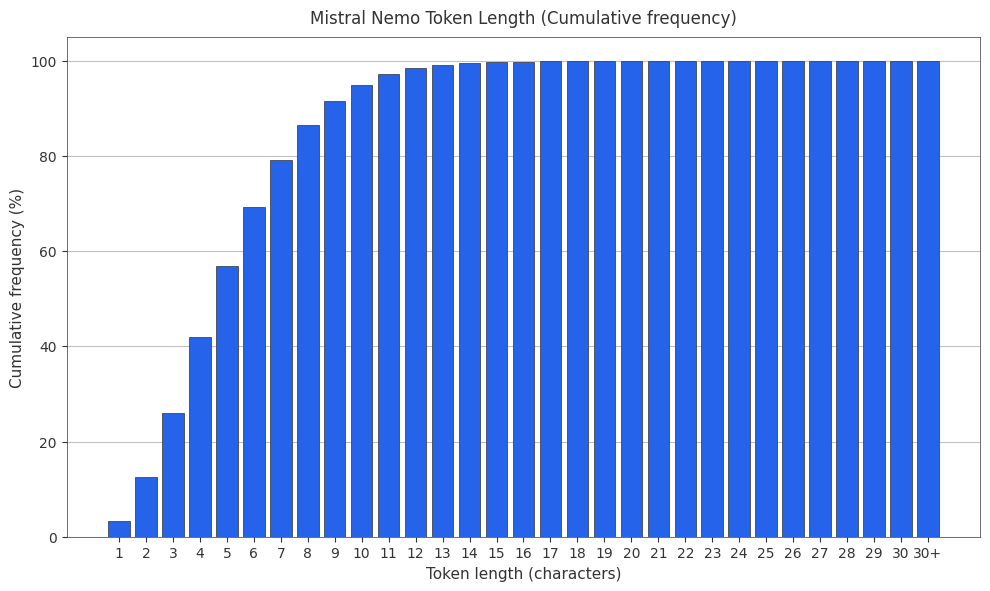
The Mistral Nemo (Tekken) Tokenizer
Mistral Nemo uses the Tekken tokenizer, a tiktoken-based tokenizer trained on 100+ languages with a 128k vocabulary size.
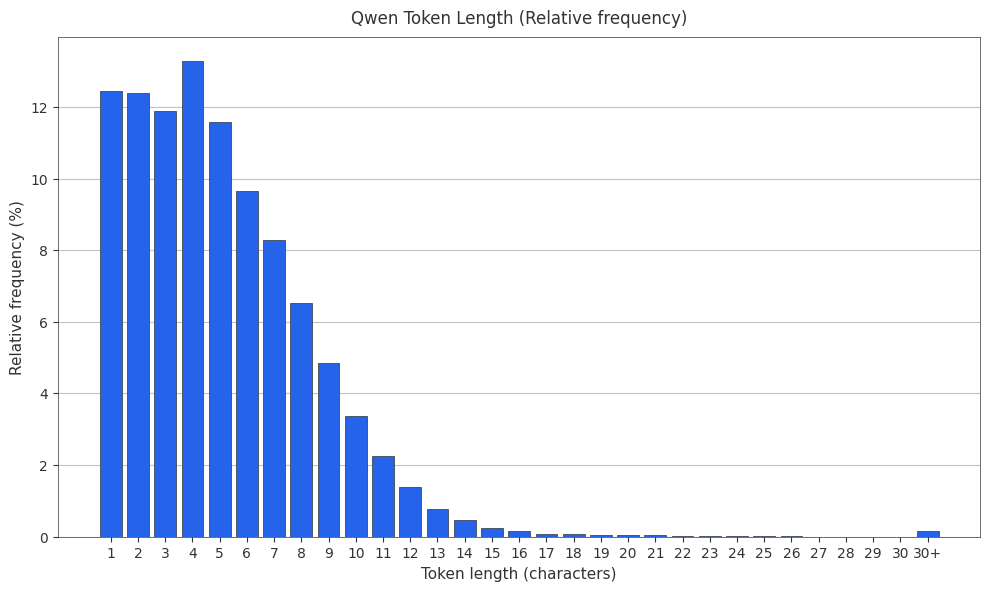
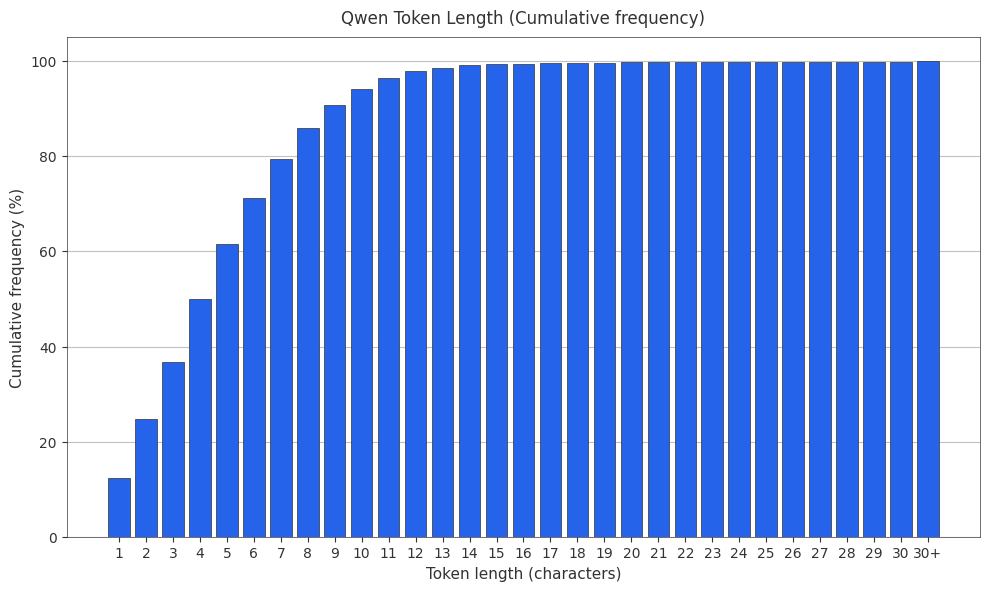
The Qwen Tokenizer
Alibaba’s Qwen family uses a byte-level BPE tokenizer with ~152k vocabulary size.
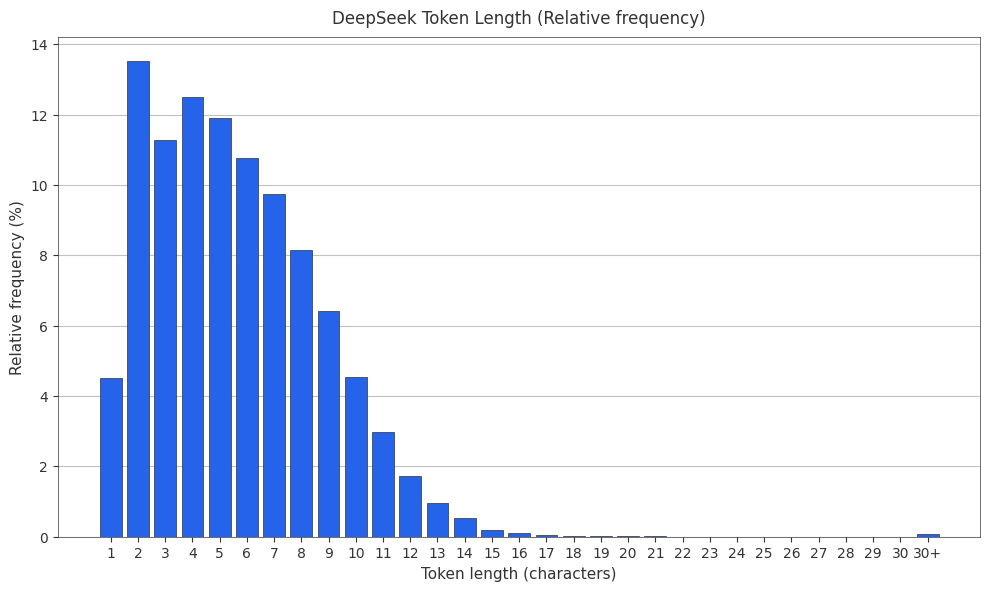
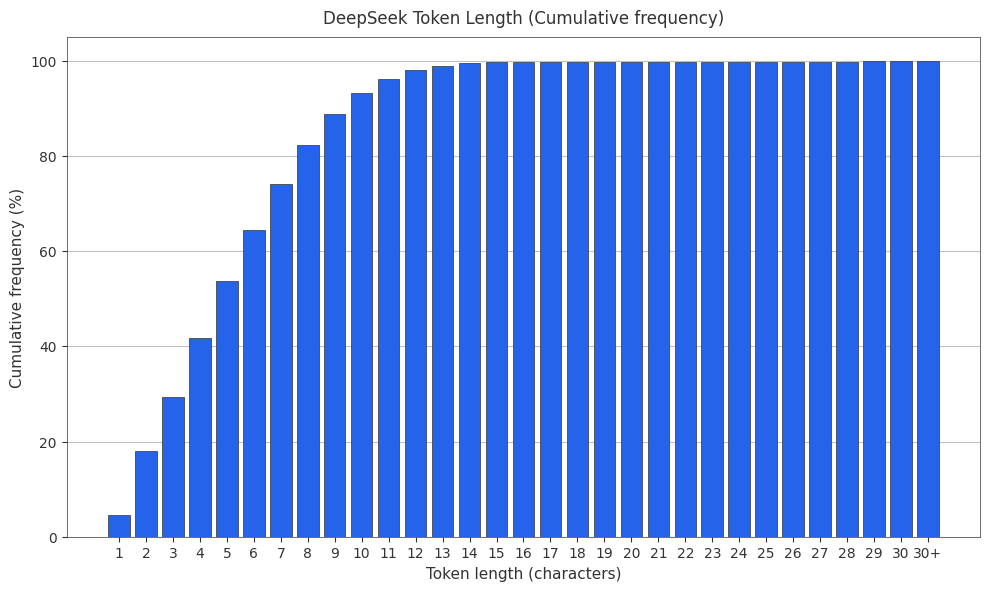
The DeepSeek Tokenizer
DeepSeek uses a byte-level BPE tokenizer with ~100k vocabulary size.